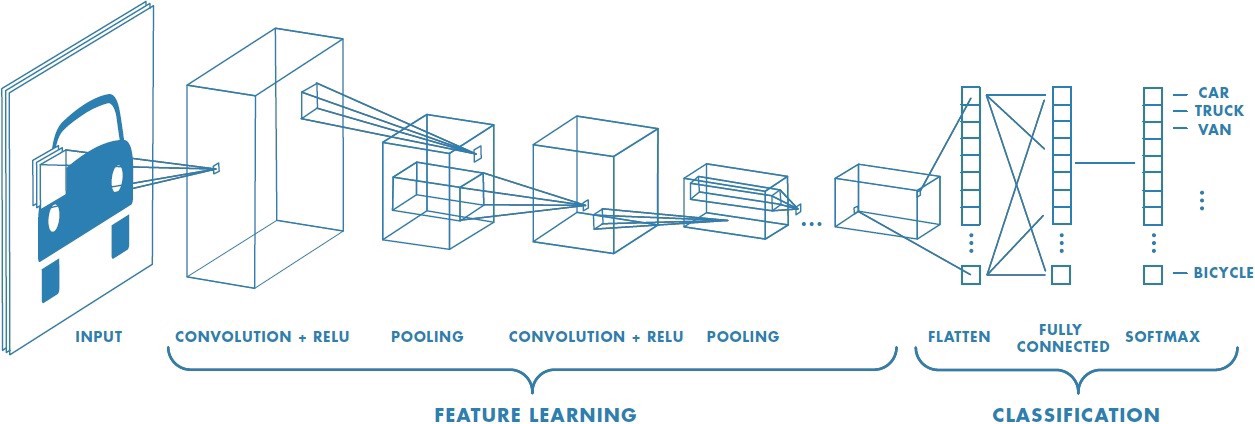
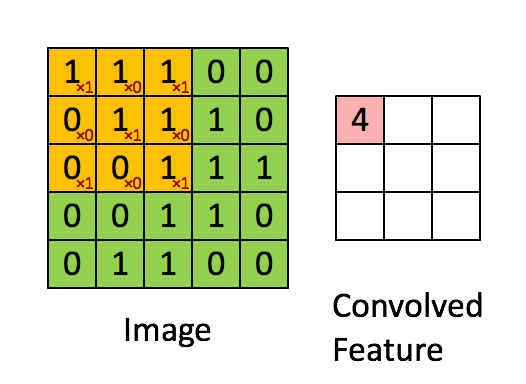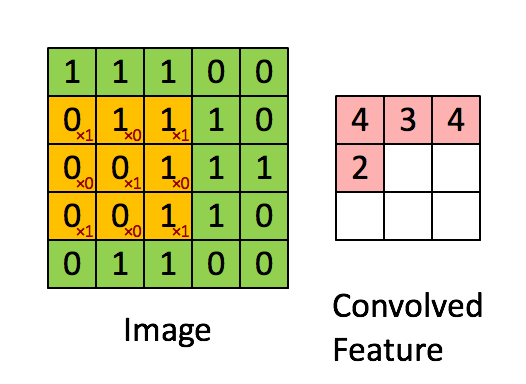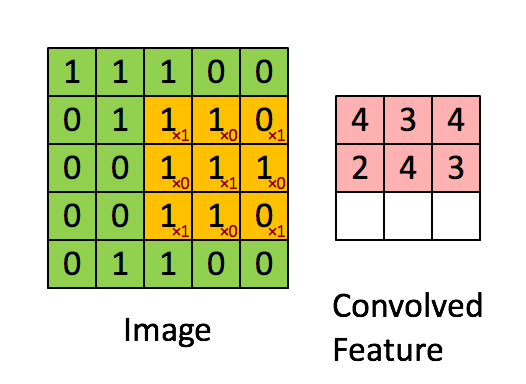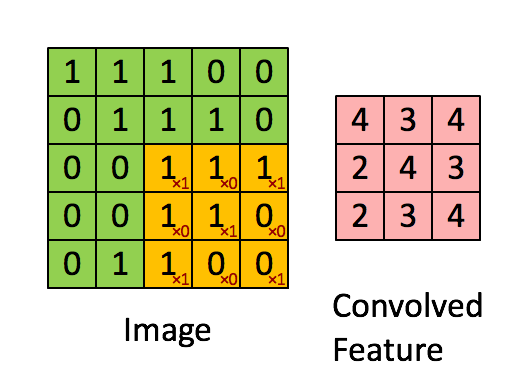
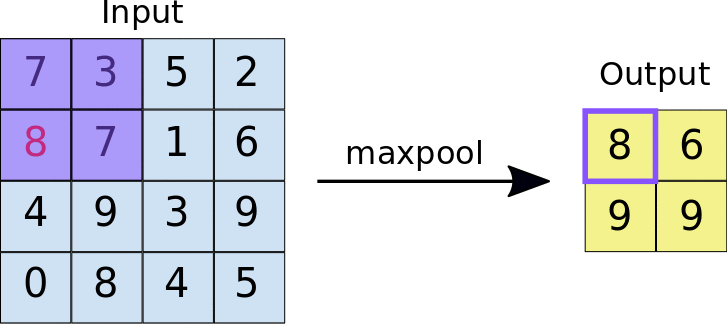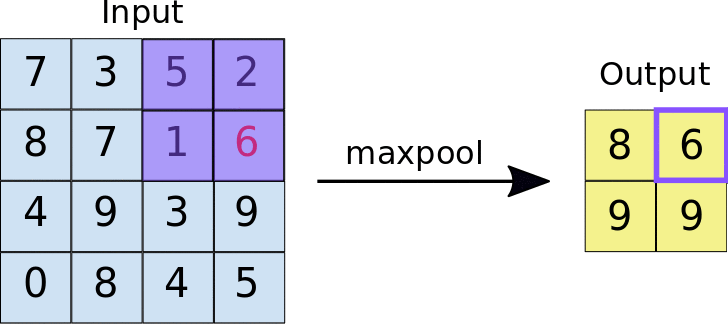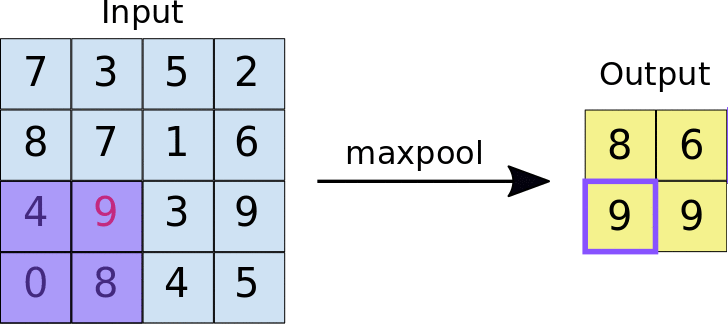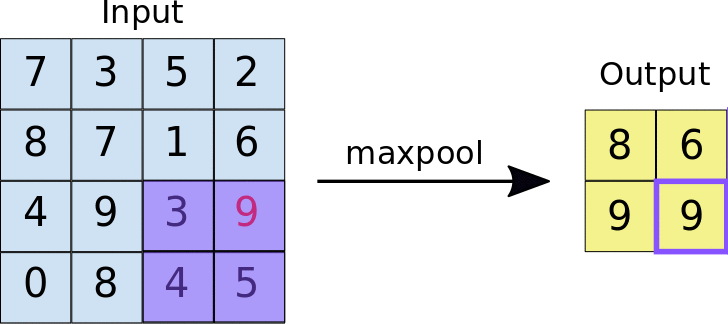
Neural Network¶
Deep learning is an exciting invention that has risen in popularity in recent years, but it's beginnings traced back to the 1950s when the earliest prototypes of artificial neural network algorithms were created. The algorithm is named so because it is inspired from our understanding at that time of how our biological brain responds to stimuli from sensory inputs. That is not to say that neural networks are valid representations of how our biological brain works - quite far from that! In fact, the over-sensationalization of neural network is in my opinion doing more harm to actual science than good.
The Architecture of Neural Network
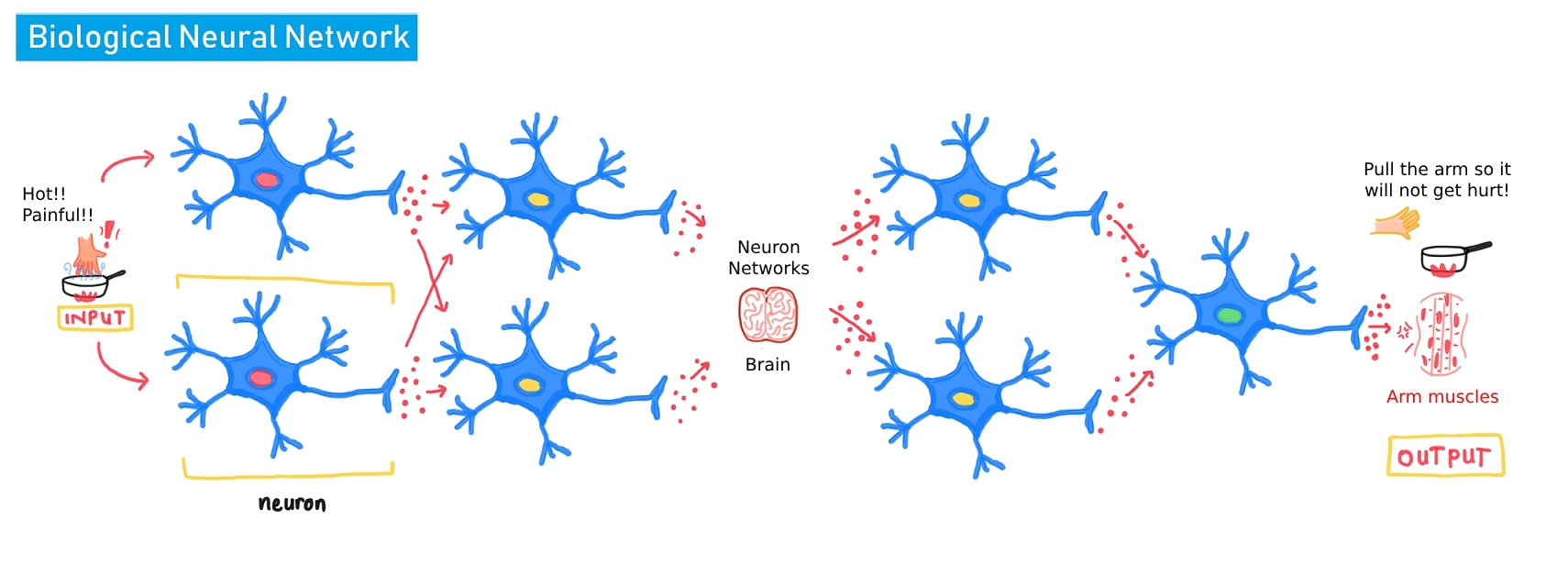
Human nerve system consist of nerve cell named Neuron and each of it combine to creates Networks. Each stimulus/ input from the outside of the body will be accepted by body senses as a signal then it will distributed from one nerve cell to another. The nerve system are spreaded from the tip of the fingers to the brain and continue to all over the body parts.
The nerve system continue to distribute the information from a stimulus/ input, processed in the brain and will be expressed as a body reaction/ activity as a given output or response.
| Human Neuron | Artificial Neural Network's Neuron |
|---|---|
 |
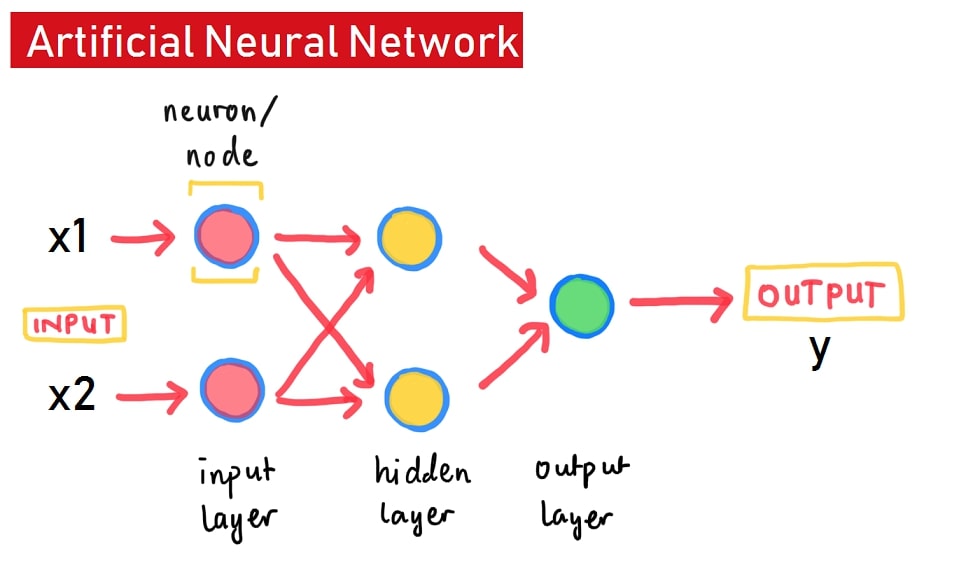 |
This is the inspiration of the creation of Neural Network Model.