Building Document Interpreter With Document Understanding Transformer(DONUT)¶
For Efficient Business Operations in Python
Background¶
Di dalam lanskap operasional bisnis yang terus berkembang dengan cepat, menguasai pemrosesan faktur yang efektif menjadi sangat penting. Pemrosesan faktur adalah bagian kritis dari kegiatan bisnis yang melibatkan pengelolaan keuangan dan akuntansi. Faktur yang diproses dengan baik membantu dalam pelacakan pengeluaran, mengoptimalkan arus kas dan memastikan kepatuhan terhadap peraturan keuangan. Dengan lanskap bisnis yang cepat berubah, perusahaan perlu dapat beradaptasi dengan cepat. Menguasai pemrosesan faktur menjadi penting untuk mengatasi ketidakpastian dan menjaga kecepatan tanggapan terhadap perubahan di sekitarnya.
Project ini fokus pada penggunaan Document Understanding Transformer, sebuah model deep learning NLP dengan pemrograman Python. Dengan menyelami teknologi ini, yang terbukti berhasil dalam tugas pemrosesan bahasa alami, kita dapat memperoleh keahlian untuk menyederhanakan dan meningkatkan alur kerja pemrosesan faktur.
Output¶
Hal yang akan dicapai, diantaranya:
- Memanfaatkan Document Understanding Transformer (Donut) untuk ekstraksi data yang akurat dari gambar penerimaan, mengoptimalkan alur kerja pemrosesan faktur.
- Meningkatkan keterampilan analisis data untuk pengambilan keputusan yang terinformasi dalam operasional bisnis dengan memanfaatkan hasil keluaran dari Document Understanding Transformer.
Utilization¶
Dalam bisnis, kebutuhan untuk mengubah gambar menjadi teks sering muncul, yang awalnya diatasi dengan teknologi OCR (Optical Character Recognition).
Namun, OCR memiliki beberapa kelemahan, yaitu:
- Memerlukan langkah-langkah preprocessing yang cukup dalam sebelum diterapkan pada OCR

- Beberapa sistem OCR terbatas dalam mengenali berbagai bahasa atau karakter khusus.
Seiring berkembangnya riset, muncul model OCR-free Document Understanding Transformer (Donut) yang mengintegrasikan arsitektur Transformer tanpa bergantung pada OCR, memungkinkan ekstraksi teks dari gambar dengan lebih akurat dan tanpa batasan bahasa.
Introduction to 🍩 Donut Model¶
What is 🍩 Donut Model?¶
Donut adalah model berbasis Transformer yang dirancang untuk tugas pemahaman dokumen yang tidak menggunakan OCR (Optical Character Recognition), menggunakan teknik mengekstrak informasi bermakna dari gambar dokumen yang tidak terstruktur.
Proses mengubah dokumen gambar menjadi output text/JSON yang dilakukan oleh model Donut melalui beberapa langkah:
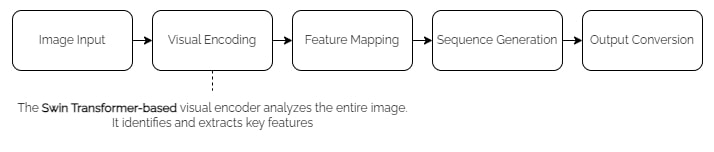
Ini meningkatkan efisiensi dan akurasi dalam pengolahan dokumen, terutama untuk dokumen dengan layout kompleks.
Transformer adalah sebuah arsitektur neural network yang diperkenalkan pada tahun 2017 dalam makalah berjudul "Attention Is All You Need" oleh Ashish Vaswani dan tim peneliti dari Google AI.
Arsitektur Transformer adalah terobosan besar dalam bidang natural language processing (NLP) dan telah mengubah cara kita mendekati tugas-tugas seperti machine translation, NLP, dan banyak aplikasi lain yang melibatkan pemrosesan sequential data. Contoh model Transformer seperti BERT, GPT (Generative Pre-trained Transformer), dan T5 (Text-to-Text Transfer Transformer)
✨ State-of-The-Art Transformer: ✨
- Mampu memahami konteks dari data sequential (misal mengetahui makna dari suatu kalimat) dengan konsep "Attention"
- Mampu bekerja secara pararel.
- Memperhatikan urutan dari data menggunakan Positional Encoding.
- Skalabilitas tinggi
- Dapat digunakan dalam berbagai konteks, termasuk pemrosesan gambar, suara, dan natural language.
Why Use 🍩 Donut Model?¶
Model Donut lebih efektif daripada OCR tradisional dalam mengenali teks dari gambar dokumen, terutama yang memiliki layout kompleks atau kualitas gambar yang rendah. Donut dapat memahami konteks dan layout dokumen secara lebih akurat dan cepat.
Selain document information extraction, Donut Model dapat melakukan berbagai tugas pemrosesan dokumen lainnya, termasuk:
- Klasifikasi Dokumen: Mengkategorikan dokumen ke dalam berbagai jenis atau kelas berdasarkan isi dan strukturnya.
- QnA: Menganalisis dan menjawab pertanyaan yang berkaitan dengan konten dalam dokumen.
💡 Tidak hanya itu, fakta menarik dari model Donut adalah bahwa model ini dilatih menggunakan teks dalam berbagai bahasa dengan memanfaatkan SynthDoG. SynthDoG adalah sebuah generator dokumen sintetis yang membantu pelatihan model Donut untuk fleksibel dalam berbagai bahasa dan domain.

Dengan menggunakan SynthDoG, Donut tidak hanya efektif dalam memahami dokumen dalam bahasa Inggris, tetapi juga dalam bahasa lain, memberikan kemampuan pemahaman dokumen yang lebih luas dan serbaguna.
How to Use 🍩 Donut Model for Document Information Extraction?¶
Model Donut bisa digunakan dalam Python dengan syarat kita telah melakukan instalasi yang diperlukan dan melakukan impor library yang diperlukan.
import re # untuk cleaning menggunakan regex (regular expression)
import os # untuk pembacaan data image -> baca nama file
import torch
import pandas as pd
from PIL import Image # untuk membaca gambar
from transformers import DonutProcessor, VisionEncoderDecoderModel
💡 Notes:
DonutProcessoradalah kelas yang digunakan untuk memproses input untuk model Donut.VisionEncoderDecoderModeladalah kelas yang mengimplementasikan arsitektur model Vision Encoder-Decoder, yang dapat digunakan untuk tugas pengolahan citra dan natural language processing.
🔻Mari kita load model donut ("naver-clova-ix/donut-base-finetuned-cord-v2") yang akan kita gunakan
⚠️ It will take longer if it's your first time loading it.
"cord-v2" -> untuk task document extraction
processor = DonutProcessor.from_pretrained("naver-clova-ix/donut-base-finetuned-cord-v2")
model = VisionEncoderDecoderModel.from_pretrained("naver-clova-ix/donut-base-finetuned-cord-v2")
Could not find image processor class in the image processor config or the model config. Loading based on pattern matching with the model's feature extractor configuration.
# set model device
device = "cuda" if torch.cuda.is_available() else "cpu"
model.to(device)
VisionEncoderDecoderModel(
(encoder): DonutSwinModel(
(embeddings): DonutSwinEmbeddings(
(patch_embeddings): DonutSwinPatchEmbeddings(
(projection): Conv2d(3, 128, kernel_size=(4, 4), stride=(4, 4))
)
(norm): LayerNorm((128,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.0, inplace=False)
)
(encoder): DonutSwinEncoder(
(layers): ModuleList(
(0): DonutSwinStage(
(blocks): ModuleList(
(0-1): 2 x DonutSwinLayer(
(layernorm_before): LayerNorm((128,), eps=1e-05, elementwise_affine=True)
(attention): DonutSwinAttention(
(self): DonutSwinSelfAttention(
(query): Linear(in_features=128, out_features=128, bias=True)
(key): Linear(in_features=128, out_features=128, bias=True)
(value): Linear(in_features=128, out_features=128, bias=True)
(dropout): Dropout(p=0.0, inplace=False)
)
(output): DonutSwinSelfOutput(
(dense): Linear(in_features=128, out_features=128, bias=True)
(dropout): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DonutSwinDropPath(p=0.1)
(layernorm_after): LayerNorm((128,), eps=1e-05, elementwise_affine=True)
(intermediate): DonutSwinIntermediate(
(dense): Linear(in_features=128, out_features=512, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output): DonutSwinOutput(
(dense): Linear(in_features=512, out_features=128, bias=True)
(dropout): Dropout(p=0.0, inplace=False)
)
)
)
(downsample): DonutSwinPatchMerging(
(reduction): Linear(in_features=512, out_features=256, bias=False)
(norm): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
)
)
(1): DonutSwinStage(
(blocks): ModuleList(
(0-1): 2 x DonutSwinLayer(
(layernorm_before): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(attention): DonutSwinAttention(
(self): DonutSwinSelfAttention(
(query): Linear(in_features=256, out_features=256, bias=True)
(key): Linear(in_features=256, out_features=256, bias=True)
(value): Linear(in_features=256, out_features=256, bias=True)
(dropout): Dropout(p=0.0, inplace=False)
)
(output): DonutSwinSelfOutput(
(dense): Linear(in_features=256, out_features=256, bias=True)
(dropout): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DonutSwinDropPath(p=0.1)
(layernorm_after): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(intermediate): DonutSwinIntermediate(
(dense): Linear(in_features=256, out_features=1024, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output): DonutSwinOutput(
(dense): Linear(in_features=1024, out_features=256, bias=True)
(dropout): Dropout(p=0.0, inplace=False)
)
)
)
(downsample): DonutSwinPatchMerging(
(reduction): Linear(in_features=1024, out_features=512, bias=False)
(norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
)
)
(2): DonutSwinStage(
(blocks): ModuleList(
(0-13): 14 x DonutSwinLayer(
(layernorm_before): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(attention): DonutSwinAttention(
(self): DonutSwinSelfAttention(
(query): Linear(in_features=512, out_features=512, bias=True)
(key): Linear(in_features=512, out_features=512, bias=True)
(value): Linear(in_features=512, out_features=512, bias=True)
(dropout): Dropout(p=0.0, inplace=False)
)
(output): DonutSwinSelfOutput(
(dense): Linear(in_features=512, out_features=512, bias=True)
(dropout): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DonutSwinDropPath(p=0.1)
(layernorm_after): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(intermediate): DonutSwinIntermediate(
(dense): Linear(in_features=512, out_features=2048, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output): DonutSwinOutput(
(dense): Linear(in_features=2048, out_features=512, bias=True)
(dropout): Dropout(p=0.0, inplace=False)
)
)
)
(downsample): DonutSwinPatchMerging(
(reduction): Linear(in_features=2048, out_features=1024, bias=False)
(norm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
)
)
(3): DonutSwinStage(
(blocks): ModuleList(
(0-1): 2 x DonutSwinLayer(
(layernorm_before): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(attention): DonutSwinAttention(
(self): DonutSwinSelfAttention(
(query): Linear(in_features=1024, out_features=1024, bias=True)
(key): Linear(in_features=1024, out_features=1024, bias=True)
(value): Linear(in_features=1024, out_features=1024, bias=True)
(dropout): Dropout(p=0.0, inplace=False)
)
(output): DonutSwinSelfOutput(
(dense): Linear(in_features=1024, out_features=1024, bias=True)
(dropout): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DonutSwinDropPath(p=0.1)
(layernorm_after): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(intermediate): DonutSwinIntermediate(
(dense): Linear(in_features=1024, out_features=4096, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output): DonutSwinOutput(
(dense): Linear(in_features=4096, out_features=1024, bias=True)
(dropout): Dropout(p=0.0, inplace=False)
)
)
)
)
)
)
(pooler): AdaptiveAvgPool1d(output_size=1)
)
(decoder): MBartForCausalLM(
(model): MBartDecoderWrapper(
(decoder): MBartDecoder(
(embed_tokens): Embedding(57580, 1024, padding_idx=1)
(embed_positions): MBartLearnedPositionalEmbedding(770, 1024)
(layers): ModuleList(
(0-3): 4 x MBartDecoderLayer(
(self_attn): MBartAttention(
(k_proj): Linear(in_features=1024, out_features=1024, bias=True)
(v_proj): Linear(in_features=1024, out_features=1024, bias=True)
(q_proj): Linear(in_features=1024, out_features=1024, bias=True)
(out_proj): Linear(in_features=1024, out_features=1024, bias=True)
)
(activation_fn): GELUActivation()
(self_attn_layer_norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(encoder_attn): MBartAttention(
(k_proj): Linear(in_features=1024, out_features=1024, bias=True)
(v_proj): Linear(in_features=1024, out_features=1024, bias=True)
(q_proj): Linear(in_features=1024, out_features=1024, bias=True)
(out_proj): Linear(in_features=1024, out_features=1024, bias=True)
)
(encoder_attn_layer_norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(final_layer_norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
)
)
(layernorm_embedding): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(layer_norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
)
)
(lm_head): Linear(in_features=1024, out_features=57580, bias=False)
)
)
Document Information Extraction Using Donut¶
Untuk melakukan ekstraksi informasi dari dokumen, langkah pertama yang perlu dilakukan adalah menyiapkan gambar-gambar dokumen yang akan dibaca. Oleh karena itu, kita akan mencoba membaca beberapa file invoice yang terdapat pada folder data_input_LBB.
1️⃣ Read Document Images¶
# folder path
dir_path = 'data_input_LBB/'
- Mari membuat dua list,
img_filenamesuntuk menyimpan nama file dengan ekstensi .png,labelsuntuk menyimpan nama file dengan ekstensi .txt (Jika Ada)
Hasilnya, dua list tersebut berisi nama file gambar dan label teks dari dokumen gambar yang kita miliki.
img_filenames = [] # list nama file gambar
images = [] # list objek gambar
labels = [] # list label dari gambar
# iterasi direktori -> looping untuk mendapatkan seluruh nama file di `data_input_LBB/valid``
for file in os.listdir(dir_path):
if file.endswith(('.png', '.jpg', '.jpeg')): # jika file tsb berekstensi ('.png', '.jpg', '.jpeg')
# menyimpan nama gambar ke list
img_filenames.append(file)
# membuka dan menyimpan objek gambar ke list
images.append(Image.open(dir_path + file))
elif file.endswith('.txt'): # jika file tersebut berekstensi .txt
# membuka file teks dan membaca isinya, lalu menyimpan ke list
with open(dir_path + file, 'r') as label_file:
labels.append(label_file.read())
# mencetak list nama file gambar
print(img_filenames)
['img_20190511_084303.jpg', 'Shilin1.jpg', 'Shilin2.jpg', 'Shilin3.jpg', 'Shilin4.jpg', 'Shilin5.jpg']
images[4]

2️⃣ Document Pre-processing¶
Sebagaimana umumnya pada model deep learning, diperlukan penyesuaian bentuk input sebelum dapat digunakan untuk prediksi atau pemrosesan lebih lanjut. Dalam konteks Donut Model, tahap ini melibatkan konversi gambar ke dalam format tensor dengan cara yang sederhana menggunakan alat yang disebut Donut Processor.
🎯 Proses ini diperlukan karena model, terutama yang menggunakan framework seperti PyTorch, umumnya membutuhkan input dalam bentuk tensor.
# code here
images[4].size
(312, 416)
pixel_values = processor(images[4], return_tensors="pt").pixel_values
pixel_values.shape
torch.Size([1, 3, 1280, 960])
✨ Keterangan:
Makna ukuran pada tensor tersebut adalah [jumlah batch, jumlah channel (RGB), tinggi, lebar]. Dalam konteks ini, semua gambar diproses menjadi ukuran yang sama sebelum masuk ke model. Hal ini dilakukan karena model deep learning seringkali mensyaratkan agar seluruh input memiliki dimensi yang konsisten.
3️⃣ Sequence Generation¶
Selanjutnya, kita membiarkan model Donut secara otoregresif menghasilkan data terstruktur, mengggunakan metode .generate().
task_prompt = "<s_cord-v2>"
✨ Secara umum, model Donut dapat digunakan untuk berbagai tugas, seperti:
- Pemrosesan/Ekstraksi Dokumen (
<s_cord-v2) - Klasifikasi Dokumen
- Pertanyaan dan Jawaban Visual (VQA) pada Dokumen
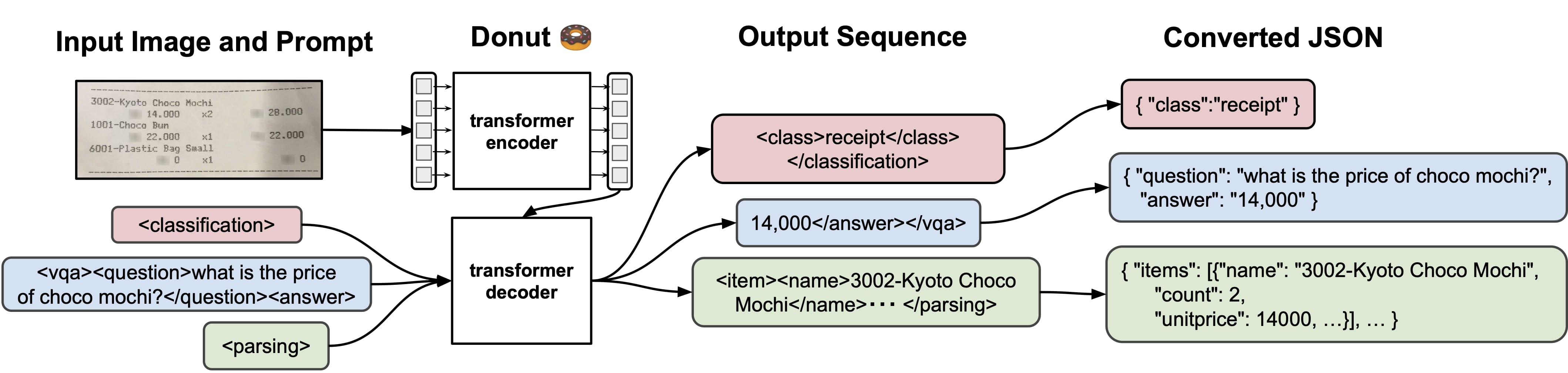
Oleh karena itu, ketika ingin menggunakan model untuk salah satu dari tugas-tugas tersebut, kita perlu menentukan task_prompt agar mengarahkan model Donut untuk fokus pada tugas spesifik yang diinginkan, sehingga output yang dihasilkan dapat lebih relevan dan bermakna sesuai dengan kebutuhan pengguna.
Selengkapnya dapat di cek di Official Github Donut
outputs = model.generate(
inputs=pixel_values.to(device), # memasukkan input
max_length=model.decoder.config.max_position_embeddings,
# parameter penting untuk set bahwa kita mau melakukan task document extraction
decoder_input_ids=processor.tokenizer(task_prompt, add_special_tokens=False, return_tensors="pt")["input_ids"].to(device),
pad_token_id=processor.tokenizer.pad_token_id, # padding
eos_token_id=processor.tokenizer.eos_token_id, # end of sentence
bad_words_ids=[[processor.tokenizer.unk_token_id]],
return_dict_in_generate=True,
use_cache=True,
# modify parameters
early_stopping=True,
num_beams=2,
output_scores=True,
)
outputs.sequences
tensor([[57579, 57526, 57528, 48809, 53845, 34306, 26492, 57527, 57530, 1314,
57529, 57532, 9066, 34504, 57531, 57548, 57528, 20220, 53314, 9066,
57527, 57530, 1314, 57529, 57532, 50891, 57531, 57547, 57525, 57534,
57536, 9066, 34504, 57535, 57533, 57544, 57546, 9066, 34504, 57545,
57564, 26635, 53692, 57563, 57556, 1314, 57555, 57543, 2]])
✨ Fungsi model.generate() pada model Donut memungkinkan untuk menghasilkan sequence text dari model. Parameter utama-utama adalah berikut
inputs: Nilai piksel dari gambar yang digunakan sebagai input untuk di-generate from doc to text.max_length: Panjang maksimum dari urutan yang dihasilkan.decoder_input_ids: ID input untuk dekoder. Di sini, tokenizer memprosestask_prompt(prompt tugas yang ditentukan) dan menghasilkan ID yang relevan.add_special_tokens=FalseMenunjukkan bahwa token khusus tidak ditambahkan dalam proses tokenisasi.pad_token_id: ID dari token padding.eos_token_id: ID dari token akhir urutan.bad_words_ids: Daftar ID kata yang harus dihindari oleh model saat melakukan generasi.return_dict_in_generate: Mengembalikan output dalam format dictionary yang lebih mudah diakses.use_cache: Menentukan apakah hasil perhitungan sebelumnya harus disimpan untuk digunakan kembali, untuk meningkatkan efisiensi.
Parameter tambahannya adalah:
early_stopping: Jika diaturTrue, model akan berhenti menghasilkan output lebih lanjut jika syarat tertentu terpenuhi, seperti mencapai EOS token.num_beams: Jumlah beams yang digunakan dalam pencarian beam.output_scores: Apakah mengembalikan skor skor untuk setiap token yang dihasilkan bersamaan dengan teks.
📌 Untuk informasi lebih rinci, silahkan merujuk ke dokumentasi 🍩 Donut di sini.
4️⃣ Document Post-Processing: Sequence Token Cleaning¶
🔻 Output hasil generate dokumen menggunakan model Donut adalah tensor yang berisi sequence token-token yang perlu dilakukan decode sehingga kita dapat mengetahui isinya. Setiap angka dalam tensor ini merepresentasikan suatu token dalam model.
🔻Maka dari itu, mari kita lakukan decode menggunakan processor yang sebelumnya juga digunakan untuk mengencode dengan menggunakan perintah processor.batch_decode()
raw_sequence = processor.batch_decode(outputs.sequences)[0]
print(raw_sequence)
<s_cord-v2><s_menu><s_nm> PDFMereeka Blackberry</s_nm><s_cnt> 1</s_cnt><s_price> 35,000</s_price><s_sub><s_nm> - Level 3</s_nm><s_cnt> 1</s_cnt><s_price> 0</s_price></s_sub></s_menu><s_sub_total><s_subtotal_price> 35,000</s_subtotal_price></s_sub_total><s_total><s_total_price> 35,000</s_total_price><s_creditcardprice> 35.000</s_creditcardprice><s_menuqty_cnt> 1</s_menuqty_cnt></s_total></s>
✨ Ini adalah teks terstruktur yang telah didekode dari tensor. Teks ini mencakup informasi terkait pesanan menu, jumlah, harga, dan total pembayaran. Strukturnya mencakup tag-tag XML (<s_cord-v2>, <s_menu>, <s_nm>, <s_cnt>, <s_price>, <sep/>, <s_total>, <s_total_price>, <s_creditcardprice>) yang memberikan konteks terhadap data yang terkandung.
🔻 Selanjutnya, dilakukan pembersihan terhadap teks. Tahap ini mencakup penghapusan token EOS (</s>), token PAD (<pad>), dan tag pertama <s_cord-v2> yang menandakan awal dari tugas pertama
sequence = raw_sequence.replace(processor.tokenizer.eos_token, "").replace(processor.tokenizer.pad_token, "") # remove </s> eos and <pad> token
sequence = re.sub(r"<.*?>", "", sequence, count=1).strip() # remove <s_cord-v2> first task start token
sequence
'<s_menu><s_nm> PDFMereeka Blackberry</s_nm><s_cnt> 1</s_cnt><s_price> 35,000</s_price><s_sub><s_nm> - Level 3</s_nm><s_cnt> 1</s_cnt><s_price> 0</s_price></s_sub></s_menu><s_sub_total><s_subtotal_price> 35,000</s_subtotal_price></s_sub_total><s_total><s_total_price> 35,000</s_total_price><s_creditcardprice> 35.000</s_creditcardprice><s_menuqty_cnt> 1</s_menuqty_cnt></s_total>'
5️⃣ Output Conversion: Token to JSON¶
✨ Output dari model Donut yang dihasilkan dapat kita ubah menjadi format JSON (JavaScript Object Notation), di Python mirip dengan dictionary, untuk memudahkan pengolahan dan analisis lebih lanjut. Format JSON/ dictionary memungkinkan representasi data yang terstruktur dan mudah diakses.
Kita dapat menggunakan metode token2json() untuk melakukan hal tersebut.
# code here: token to json
processor.token2json(sequence)
{'menu': {'nm': 'PDFMereeka Blackberry',
'cnt': '1',
'price': '35,000',
'sub': {'nm': '- Level 3', 'cnt': '1', 'price': '0'}},
'sub_total': {'subtotal_price': '35,000'},
'total': {'total_price': '35,000',
'creditcardprice': '35.000',
'menuqty_cnt': '1'}}
# gambar yang di generate
images[4]
🔻 Mari kita coba men-generate keseluruhan gambar receipt/invoice yang kita miliki!
💡 Untuk memudahkan dan mengotomatisasi proses ini, khususnya ketika bekerja dengan banyak gambar, kita akan menggabungkan seluruh langkah, dari 1 hingga 5, ke dalam satu fungsi. Dengan demikian, kita dapat dengan mudah menerapkan fungsi ini pada banyak gambar secara berurutan melalui looping.
def doc_to_text(input_img, task_prompt=task_prompt, model=model, processor=processor):
# set model device
device = "cuda" if torch.cuda.is_available() else "cpu"
model.to(device)
# document preprocessing
pixel_values = processor(input_img, return_tensors="pt").pixel_values
decoder_input_ids = processor.tokenizer(task_prompt, add_special_tokens=False, return_tensors="pt")["input_ids"]
# sequence generation
outputs = model.generate(
pixel_values.to(device),
decoder_input_ids=decoder_input_ids.to(device),
max_length=model.decoder.config.max_position_embeddings,
pad_token_id=processor.tokenizer.pad_token_id,
eos_token_id=processor.tokenizer.eos_token_id,
use_cache=True,
bad_words_ids=[[processor.tokenizer.unk_token_id]],
return_dict_in_generate=True,
# modify parameters
early_stopping=True,
num_beams=2,
output_scores=True,
)
# document post-processing: sequence token cleaning
sequence = processor.batch_decode(outputs.sequences)[0]
sequence = sequence.replace(processor.tokenizer.eos_token, "").replace(processor.tokenizer.pad_token, "")
sequence = re.sub(r"<.*?>", "", sequence, count=1).strip() # remove first task start token
print(sequence)
# output conversion: token to json
output = processor.token2json(sequence)
return output
# list untuk menyimpan hasil generate docs to text
preds = []
# code here: buatlah looping untuk predict 20 image dan disimpan di preds
# step 1: looping gambar yang ada di list 'images'
for img in images[:6]:
#step 2: kita mengenerate 1 per 1 dari gambarnya
result = doc_to_text(img)
preds.append(result)
<s_menu><s_nm> Bread Butter Pudding</s_nm><s_cnt> 1</s_cnt><s_price> 11,500</s_price><sep/><s_nm> Cream Bruille</s_nm><s_cnt> 1</s_cnt><s_price> 14,000</s_price><sep/><s_nm> Choco Croissant</s_nm><s_cnt> 1</s_cnt><s_price> 10,500</s_price><sep/><s_nm> Bank Of Chocolat</s_nm><s_cnt> 1</s_cnt><s_price> 7,500</s_price></s_menu><s_sub_total><s_subtotal_price> 43,500</s_subtotal_price></s_sub_total><s_total><s_total_price> 43,500</s_total_price></s_total> <s_menu><s_nm> XXL Crispy Chicken</s_nm><s_cnt> 1</s_cnt><s_price> 42,000</s_price><s_sub><s_nm> - Tidak Pedas</s_nm><s_cnt> 1</s_cnt><s_price> 0</s_price></s_sub></s_menu><s_sub_total><s_subtotal_price> 42,000</s_subtotal_price></s_sub_total><s_total><s_total_price> 42,000</s_total_price><s_menuqty_cnt> 1</s_menuqty_cnt></s_total> <s_menu><s_nm> BBQ Chicken</s_nm><s_cnt> 1</s_cnt><s_price> 42,000</s_price><s_sub><s_nm> - Pedas</s_nm><s_cnt> 1</s_cnt><s_price> 0</s_price></s_sub></s_menu><s_sub_total><s_subtotal_price> 42,000</s_subtotal_price></s_sub_total><s_total><s_total_price> 42,000</s_total_price><s_menuqty_cnt> 1</s_menuqty_cnt></s_total> <s_menu><s_nm> Seaweed Chicken</s_nm><s_cnt> 1</s_cnt><s_price> 43,000</s_price><s_sub><s_nm> Tidak Pedas</s_nm><s_cnt> 1</s_cnt><s_price> 0</s_price></s_sub></s_menu><s_sub_total><s_subtotal_price> 43,000</s_subtotal_price></s_sub_total><s_total><s_total_price> 43,000</s_total_price><s_menuqty_cnt> 1</s_menuqty_cnt></s_total> <s_menu><s_nm> PDFMereeka Blackberry</s_nm><s_cnt> 1</s_cnt><s_price> 35,000</s_price><s_sub><s_nm> - Level 3</s_nm><s_cnt> 1</s_cnt><s_price> 0</s_price></s_sub></s_menu><s_sub_total><s_subtotal_price> 35,000</s_subtotal_price></s_sub_total><s_total><s_total_price> 35,000</s_total_price><s_creditcardprice> 35.000</s_creditcardprice><s_menuqty_cnt> 1</s_menuqty_cnt></s_total> <s_menu><s_nm> Happy Rice Box</s_nm><s_cnt> 1</s_cnt><s_price> 42,000</s_price><s_sub><s_nm> - Sedang</s_nm><s_cnt> 1</s_cnt><s_price> 0</s_price></s_sub><sep/><s_nm> - Dine In</s_nm><s_cnt> 1</s_cnt><s_price> 0</s_price></s_sub><sep/><s_nm> Mineral Water 330 ml*</s_nm><s_cnt> 1</s_cnt><s_price> 6,000</s_price></s_sub></s_menu><s_sub_total><s_subtotal_price> 48,000</s_subtotal_price></s_sub_total><s_total><s_total_price> 48,000</s_total_price><s_menuqty_cnt> 2</s_menuqty_cnt></s_total>
# code here: cek hasil prediksinya
preds[4]
{'menu': {'nm': 'PDFMereeka Blackberry',
'cnt': '1',
'price': '35,000',
'sub': {'nm': '- Level 3', 'cnt': '1', 'price': '0'}},
'sub_total': {'subtotal_price': '35,000'},
'total': {'total_price': '35,000',
'creditcardprice': '35.000',
'menuqty_cnt': '1'}}
Data Analysis Enhancement with Donut Outputs¶
Agar mempermudah dalam kita menganalisis hasil model Donut maka kita perlu mengubah data generated text tersebut menjadi sebuah tabel.
Transform Donut Outputs to Dataframe pandas¶
Kita cukup menggunakan pd.DataFrame.from_dict(), pandas secara otomatis mengonversi struktur JSON tersebut ke dalam bentuk tabel.
df_preds = pd.DataFrame.from_dict(preds)
df_preds
| menu | sub_total | total | |
|---|---|---|---|
| 0 | [{'nm': 'Bread Butter Pudding', 'cnt': '1', 'p... | {'subtotal_price': '43,500'} | {'total_price': '43,500'} |
| 1 | {'nm': 'XXL Crispy Chicken', 'cnt': '1', 'pric... | {'subtotal_price': '42,000'} | {'total_price': '42,000', 'menuqty_cnt': '1'} |
| 2 | {'nm': 'BBQ Chicken', 'cnt': '1', 'price': '42... | {'subtotal_price': '42,000'} | {'total_price': '42,000', 'menuqty_cnt': '1'} |
| 3 | {'nm': 'Seaweed Chicken', 'cnt': '1', 'price':... | {'subtotal_price': '43,000'} | {'total_price': '43,000', 'menuqty_cnt': '1'} |
| 4 | {'nm': 'PDFMereeka Blackberry', 'cnt': '1', 'p... | {'subtotal_price': '35,000'} | {'total_price': '35,000', 'creditcardprice': '... |
| 5 | [{'nm': 'Happy Rice Box', 'cnt': '1', 'price':... | {'subtotal_price': '48,000'} | {'total_price': '48,000', 'menuqty_cnt': '2'} |
🔻 Mari kita cek missing value-nya menggunakan metode isna().sum()
# code here
df_preds.isna().sum()
menu 0 sub_total 0 total 0 dtype: int64
📈 Insight: Dalam kasus kali ini kolom sub_total akan diabaikan karena kita akan mencoba mengambil total harga keseluruhan, harga per item dan jumlah per item saja.
Data Wrangling¶
🔻 Untuk memudahkan analisis, kita akan memecah data ini sehingga setiap item pada struk diwakili dalam baris tersendiri. Pendekatan ini akan mempermudah pengolahan dan analisis data.
- Membuat dataframe kosong untuk menjadi tempat pengisian data kita.
df = pd.DataFrame(columns=['nm', 'cnt', 'price', 'total_price'])
df
| nm | cnt | price | total_price |
|---|
# cara mengecek jumlah baris pada suatu dataframe
len(df)
0
- Memasukkan seluruh data pada
df_predskedfdengan memanfaatkan looping.iterrows().
💡 .iterrows() merupakan metode pada objek DataFrame yang menghasilkan pasangan (index, row) untuk DataFrame tersebut
# mengiterasi setiap rrow dalam df_preds
for index, row in df_preds.iterrows(): #index: baris ke berapa, row: nilai dari barisnya
# mengecek apakah field 'menu' adalah list, jika tidak, ubah menjadi list
menus = row['menu'] if isinstance(row['menu'], list) else [row['menu']]
# mengiterasi setiap elemen dalam list 'menus'
for menu in menus:
# menambahkan row baru ke 'df' dengan informasi dari 'menu' serta tambahan 'total_price' dan 'receipt_id'
df.loc[len(df)] = {
**menu, # unpack semua pasangan key-value dari dictionary 'menu' yang cocok dg nama kolom yg ada
'total_price': row['total']['total_price'] # mengambil 'total_price' dari baris saat ini
#'receipt_id': img_filenames[index].split('.')[0] # Jika ada, mengambil ID struk dari nama file gambar
}
💡**dict : Melakukan unpack semua pasangan key-value dari dictionary 'dict'
💡df.loc[] : Metode yang digunakan untuk mengakses baris atau kolom tertentu dari DataFrame berdasarkan nama/labelnya
df
| nm | cnt | price | total_price | |
|---|---|---|---|---|
| 0 | Bread Butter Pudding | 1 | 11,500 | 43,500 |
| 1 | Cream Bruille | 1 | 14,000 | 43,500 |
| 2 | Choco Croissant | 1 | 10,500 | 43,500 |
| 3 | Bank Of Chocolat | 1 | 7,500 | 43,500 |
| 4 | XXL Crispy Chicken | 1 | 42,000 | 42,000 |
| 5 | BBQ Chicken | 1 | 42,000 | 42,000 |
| 6 | Seaweed Chicken | 1 | 43,000 | 43,000 |
| 7 | PDFMereeka Blackberry | 1 | 35,000 | 35,000 |
| 8 | Happy Rice Box | 1 | 42,000 | 48,000 |
| 9 | Mineral Water 330 ml* | 1 | 6,000 | 48,000 |
🔻 Mari kita simpan data document extracted yang sudah kita lakukan agar terecord dengan baik
# menyimpan DataFrame 'df' ke dalam file csv
df.to_csv('receipt_extracted_LBB.csv',
index=False) # berarti indeks DataFrame tidak disertakan dalam file csv
Data Cleaning¶
# cek tipe data
df.info()
<class 'pandas.core.frame.DataFrame'> Index: 10 entries, 0 to 9 Data columns (total 4 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 nm 10 non-null object 1 cnt 10 non-null object 2 price 10 non-null object 3 total_price 10 non-null object dtypes: object(4) memory usage: 400.0+ bytes
🔻Mengganti nama kolom agar lebih informatif dengan menggunakan metode .rename()
new_columns_name = {
'nm': 'item_name',
'cnt': 'quantity'
}
df = df.rename(columns=new_columns_name)
df
| item_name | quantity | price | total_price | |
|---|---|---|---|---|
| 0 | Bread Butter Pudding | 1 | 11,500 | 43,500 |
| 1 | Cream Bruille | 1 | 14,000 | 43,500 |
| 2 | Choco Croissant | 1 | 10,500 | 43,500 |
| 3 | Bank Of Chocolat | 1 | 7,500 | 43,500 |
| 4 | XXL Crispy Chicken | 1 | 42,000 | 42,000 |
| 5 | BBQ Chicken | 1 | 42,000 | 42,000 |
| 6 | Seaweed Chicken | 1 | 43,000 | 43,000 |
| 7 | PDFMereeka Blackberry | 1 | 35,000 | 35,000 |
| 8 | Happy Rice Box | 1 | 42,000 | 48,000 |
| 9 | Mineral Water 330 ml* | 1 | 6,000 | 48,000 |
🔻 Jika kita lihat kembali kolom price maupun total_price seharusnya memiliki tipe data int/float. Maka dari itu kita perlu melakukan pembersihan ,.
# fungsi untuk membersihkan string harga dari simbol dan spasi
def clean_price(x):
return int(x.replace(".", "").replace(",", "").replace("Rp", "").replace(" ", ""))
💡 Gunakan fungsi apply untuk menjalankan suatu fungsi terhadap setiap elemen dalam sebuah kolom secara otomatis. Contohnya, jika kita ingin membersihkan format harga dalam kolom 'price' di DataFrame df, kita bisa melakukan hal berikut:
# mengaplikasikan fungsi 'clean_price' ke setiap elemen di kolom 'price' pada 'df'
df['price'] = df['price'].apply(lambda x: clean_price(str(x)))
df.head()
| item_name | quantity | price | total_price | |
|---|---|---|---|---|
| 0 | Bread Butter Pudding | 1 | 11500 | 43,500 |
| 1 | Cream Bruille | 1 | 14000 | 43,500 |
| 2 | Choco Croissant | 1 | 10500 | 43,500 |
| 3 | Bank Of Chocolat | 1 | 7500 | 43,500 |
| 4 | XXL Crispy Chicken | 1 | 42000 | 42,000 |
# code here: mengaplikasikan fungsi 'clean_price' ke setiap elemen di kolom 'total_price' pada 'df'
# mengaplikasikan fungsi 'clean_price' ke setiap elemen di kolom 'price' pada 'df'
df['total_price'] = df['total_price'].apply(lambda x: clean_price(str(x)))
df
| item_name | quantity | price | total_price | |
|---|---|---|---|---|
| 0 | Bread Butter Pudding | 1 | 11500 | 43500 |
| 1 | Cream Bruille | 1 | 14000 | 43500 |
| 2 | Choco Croissant | 1 | 10500 | 43500 |
| 3 | Bank Of Chocolat | 1 | 7500 | 43500 |
| 4 | XXL Crispy Chicken | 1 | 42000 | 42000 |
| 5 | BBQ Chicken | 1 | 42000 | 42000 |
| 6 | Seaweed Chicken | 1 | 43000 | 43000 |
| 7 | PDFMereeka Blackberry | 1 | 35000 | 35000 |
| 8 | Happy Rice Box | 1 | 42000 | 48000 |
| 9 | Mineral Water 330 ml* | 1 | 6000 | 48000 |
Dari dataframe diatas, dapat dilakukan proses analisa lanjutan sesuai dengan kebutuhan bisnis.
Kesimpulan¶
Berikut adalah contoh sederhana penerapan Document Understanding Transformer untuk ekstraksi dokumen dari data gambar, Task Prompt dapat disesuaikan berdasarkan kebutuhan.
Dibutuhkan beberapa tahap Data Wrangling tambahan untuk mengolah struktur data yang lebih kompleks.
Transformer ini dapat dibuatkan aplikasi web yang ramah pengguna dengan alat seperti Gradio untuk pemindaian efisien untuk faktur yang secara mulus sejalan dengan kebutuhan bisnis modern untuk proses keuangan yang efisien.